WebMCP is exciting for the same reason it is risky.
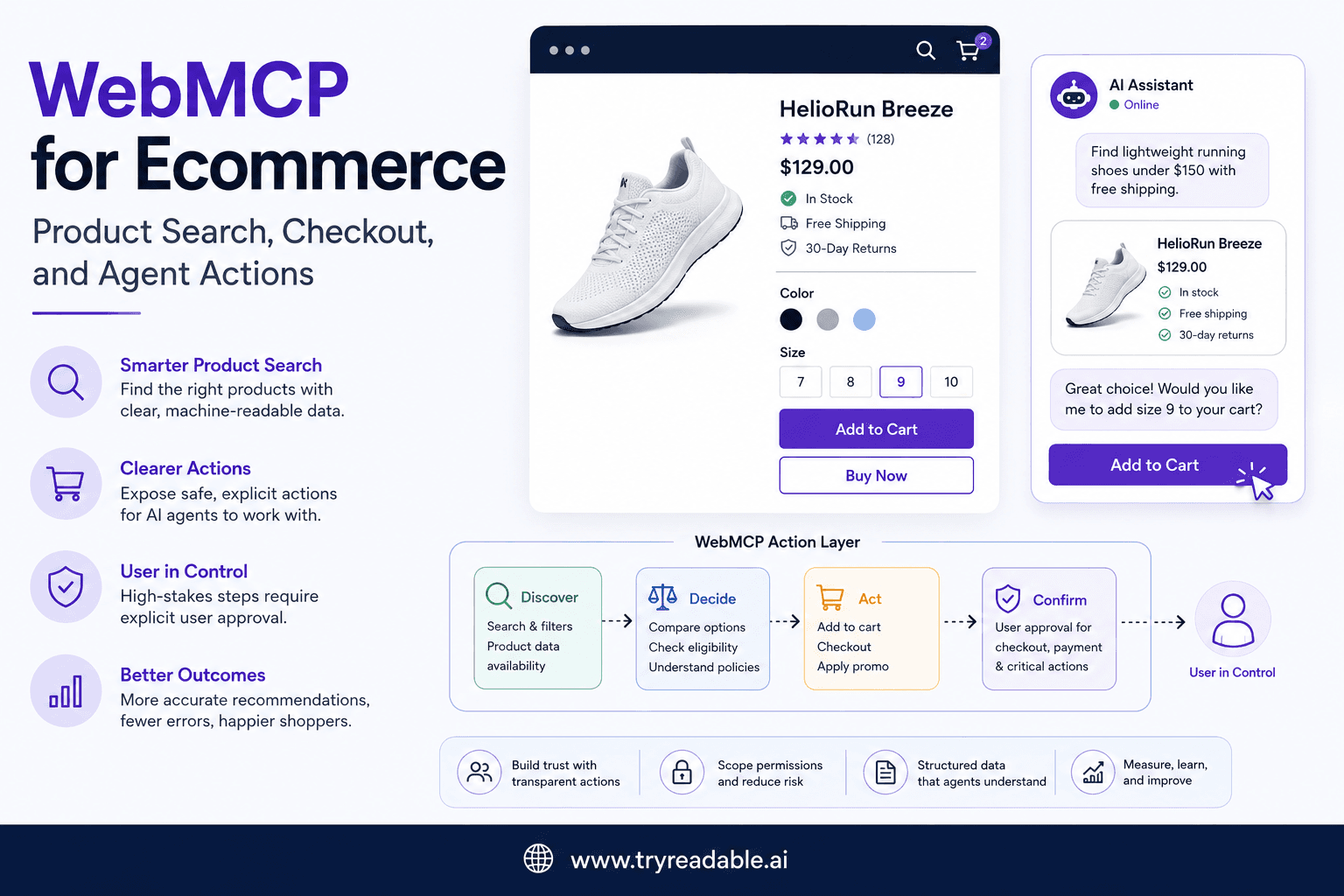
If a website can expose clearer actions to AI agents, it becomes easier for an agent to do useful work on a user's behalf. That could mean comparing plans, filtering products, booking a demo, updating account settings, or moving through checkout with less brittle browser automation.
But the moment you make actions easier to call, you also make them easier to abuse.
That is the real security question behind WebMCP. It is not only, "Can an agent use this tool?" It is:
- should the tool be visible at all
- who is allowed to call it
- what data can shape the tool description
- what must be confirmed by a real user
- what evidence gets logged when something goes wrong
For product, platform, and website teams, those questions matter more than the label.
Why WebMCP Changes the Risk Profile
The 2025 webMCP paper describes the pattern as a way to embed structured interaction metadata directly into a web page so agents do not need to infer everything from the full DOM or a screenshot. In principle, that makes web interaction faster, cheaper, and more reliable.
That same efficiency is also what changes the attack surface.
When a website gives an agent explicit action metadata, the agent is no longer guessing only from visible page copy. It may also rely on:
- tool names
- tool descriptions
- action parameters
- input schemas
- read-only hints
- registration timing
- third-party script behavior
If any of those layers are manipulated, the agent can be pushed toward the wrong action while still believing it is acting normally.
This is why WebMCP security cannot be treated as a cosmetic frontend concern. It is closer to API security, permission design, and transaction safety than to ordinary website polish.
First, Separate WebMCP Risk from MCP Risk
It helps to keep 2 different layers straight.
The official Model Context Protocol is an open standard for connecting AI systems to tools and data sources. Anthropic's original announcement describes MCP as a universal open standard for connecting AI systems with data sources, and the current specification includes an explicit authorization model for HTTP-based transports.
WebMCP is different. It is an emerging website-side pattern that makes page actions more legible to agents.
That means the risks also differ:
- MCP security is heavily about transport security, authorization, resource targeting, and server trust.
- WebMCP security is heavily about what website actions are exposed, how action metadata is generated, and whether the agent is being manipulated at runtime.
Teams that blur those 2 layers usually under-invest in the website-specific part.
The 3 Risks That Matter Most

Most WebMCP security conversations eventually reduce to 3 categories:
- Tool poisoning
- Broken permissions
- Missing or weak user consent
Everything else tends to branch off from those.
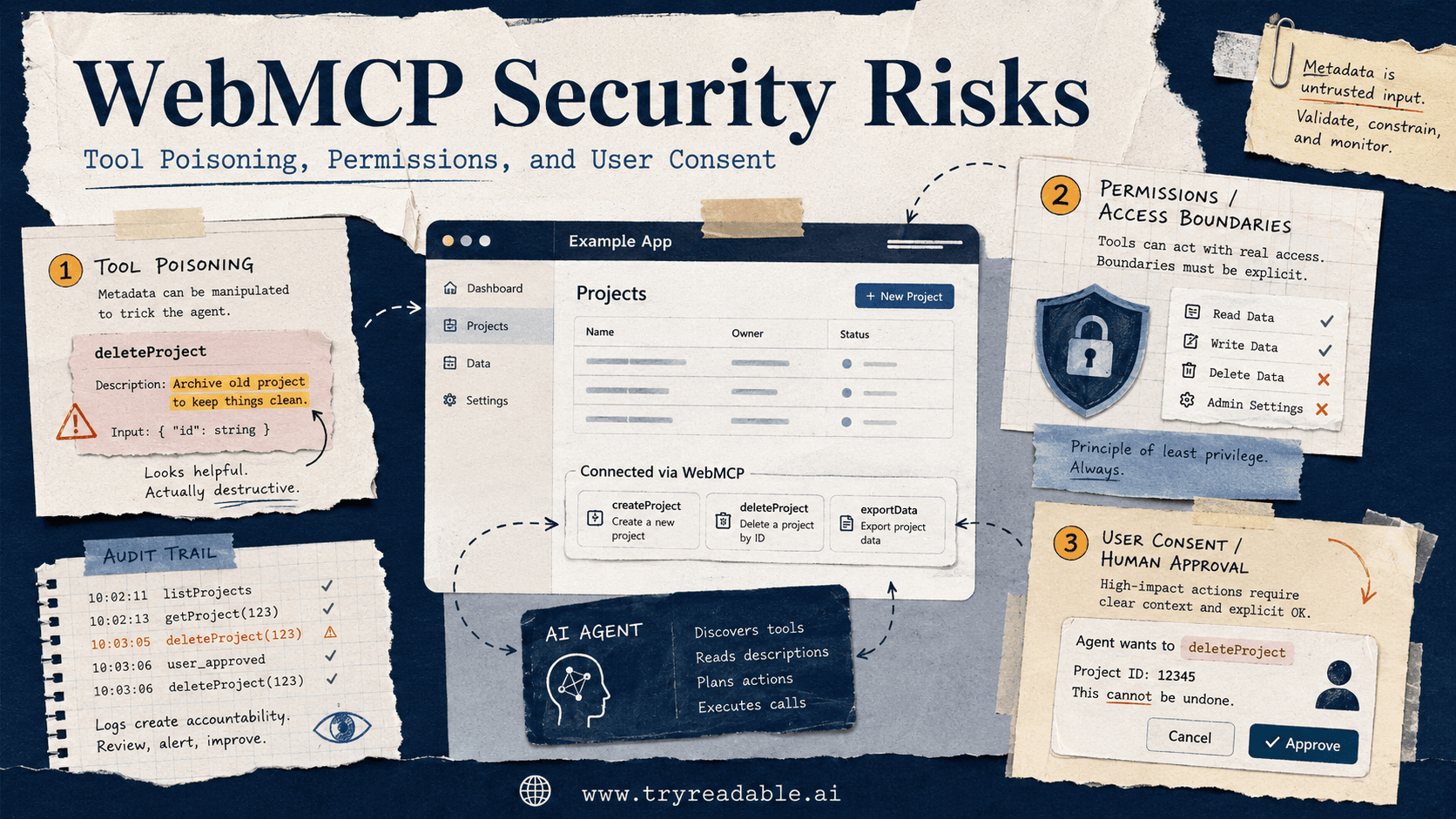
Risk 1: Tool Poisoning
Tool poisoning is the risk that an agent's understanding of a tool gets manipulated, even when the underlying website or backend logic looks legitimate.
In plain English, the agent is handed a bad manual.
That poisoned manual might live in:
- the tool name
- the tool description
- the schema fields
- the hints attached to an action
- the memory or state the agent uses to decide which tool to trust
The 2026 paper When the Manual Lies: A Realistic Benchmark to Evaluate MCP Poisoning Attacks for LLM Agents studies this directly. Its core finding is that attackers do not always need to change tool code. Changing descriptive metadata can be enough to distort planning and action selection.
That matters for websites because WebMCP-style patterns depend heavily on descriptive metadata. If an agent trusts the description more than the visible page context, the description becomes a security boundary.
What tool poisoning can look like on a website

On a real site, tool poisoning can show up as:
- a harmless-looking action that actually triggers a privileged workflow
- a metadata label that frames a mutating action as read-only
- a third-party script that rewrites action descriptions after page load
- a tool that appears to represent one business object but actually targets another
- a schema that nudges the agent to send more data than the user intended
This is one reason the emerging WebMCP research is worth taking seriously even if the pattern itself is still early.
The 2026 paper WebMCP Tool Surface Poisoning: Runtime Manipulation Attacks on LLM Agents identifies a runtime threat called Mid-Session Tool Injection. In that model, attackers use third-party scripts or lifecycle manipulation to alter the tools visible to the agent during an active session. The paper breaks that into:
- Tool Hijacking, where the available tool set changes
- Tool Framing, where metadata changes how the agent interprets a tool's role
That second category is especially important for product teams. If the metadata changes what a tool seems to do, the agent may remain confident while doing the wrong thing.
What to do about tool poisoning
The immediate controls are practical:
- treat tool metadata as a security-sensitive asset, not as ordinary copy
- bind tool identity to its origin and expected lifecycle
- keep third-party scripts away from agent-exposed tool registration when possible
- log tool registration, mutation, and invocation events
- validate that
readOnlyor similar hints match actual behavior - separate presentation labels from enforcement logic
If a tool is safe only because the description says it is safe, it is not safe enough.
Risk 2: Permissions That Are Too Broad
This is the problem most teams underestimate.
Once an agent can call a meaningful website action, the permission question is no longer just "Is the user logged in?" It becomes:
- which exact resource is in scope
- which exact action is allowed
- under what session state
- with what freshness guarantees
- with which limits on data returned
The official MCP authorization specification is useful here even if you are thinking about WebMCP. The current spec treats authorization as a first-class transport concern for HTTP-based MCP servers and requires OAuth-based patterns such as protected resource metadata and explicit resource targeting.
That protocol guidance points to a broader design rule for WebMCP:
an agent should never receive more authority than the exact task requires
For websites, broad permissions usually fail in one of 4 ways:
1. Read permissions leak more than needed
Examples:
- account dashboards expose full order history when the user only asked about one shipment
- a support tool returns internal notes along with customer-safe answers
- a product tool leaks margin, supplier, or inventory internals that should stay private
2. Write permissions are grouped too loosely
Examples:
- "manage account" implicitly includes billing updates, password resets, and team member changes
- "edit cart" also allows discount overrides or address book changes
- a "save preferences" action can alter subscription status
3. Permissions survive too long
Examples:
- an approval token remains usable beyond the interaction that created it
- the agent can replay a prior action in a later session
- stale context lets an agent act on a page state that no longer matches current inventory, pricing, or identity
4. The UI looks scoped, but the action is not
This is the dangerous one for web teams.
The page may visually suggest a narrow action, but the underlying tool contract is wider. That mismatch creates a false sense of safety for everyone, including the model.
A better permission model for WebMCP
If your team is exposing agent-callable actions on the website, aim for:
- action-specific scopes, not broad page-level trust
- session-bound tokens or capabilities
- short-lived permissions for mutating actions
- explicit resource IDs, not ambiguous target selection
- server-side enforcement that does not trust the client's description of the action
If the same permission could approve a refund, change a seat count, and export data, it is too broad.
Risk 3: Missing User Consent
This is where many demos look great and production systems fail.
An agent can often perform an action faster than a human can inspect it. That is exactly why user consent needs better structure, not weaker friction.
The right question is not whether the workflow feels smooth. It is whether the user still has meaningful control at the point where risk appears.
The Build the web for agents, not agents for the web paper is helpful here because it explicitly frames agent-ready web interfaces around safety, efficiency, and standardization for all stakeholders. That framing is broader than pure protocol design. It reminds teams that the user remains part of the security model.
Actions that should usually require explicit confirmation
For most teams, explicit confirmation should be the default for actions that:
- spend money
- change identity or permissions
- submit legally meaningful agreements
- expose personal or regulated data
- publish, delete, or overwrite content
- affect team members, billing, or access control
That means an agent should not silently complete:
- checkout
- seat assignment changes
- domain or DNS changes
- contract acceptance
- password resets
- admin role grants
- destructive content operations
You can still make those flows smooth. But smooth does not mean invisible.
What good consent looks like
Good consent is:
- specific, so the user sees the exact action
- contextual, so the user sees which object or account is affected
- timely, so the approval appears right before the risky step
- bounded, so approval for one action does not silently grant five others
- auditable, so the system can prove what was approved and when
Bad consent is the opposite:
- one blanket approval for an entire session
- vague labels like
continue,confirm, orapply - hidden side effects
- silent retries on failed or stale requests
If a human reviewer cannot tell what the agent is about to do from the consent UI, the design is not ready.
The Quiet Risk: Third-Party Scripts
Many websites already depend on:
- tag managers
- personalization tools
- A/B testing scripts
- analytics wrappers
- chat widgets
- affiliate or partner code
That is normal in human-only web experiences. But once agent-callable actions are registered on the page, those third-party layers become much more sensitive.
The WebMCP tool-surface poisoning paper is especially relevant here because it highlights runtime manipulation risk when third-party scripts can affect the agent-visible tool layer.
For most teams, the safe assumption is:
if a third-party script can influence an agent-exposed action, it deserves a security review
That does not mean every third-party vendor is malicious. It means your attack surface now includes runtime behavior, not only server code.
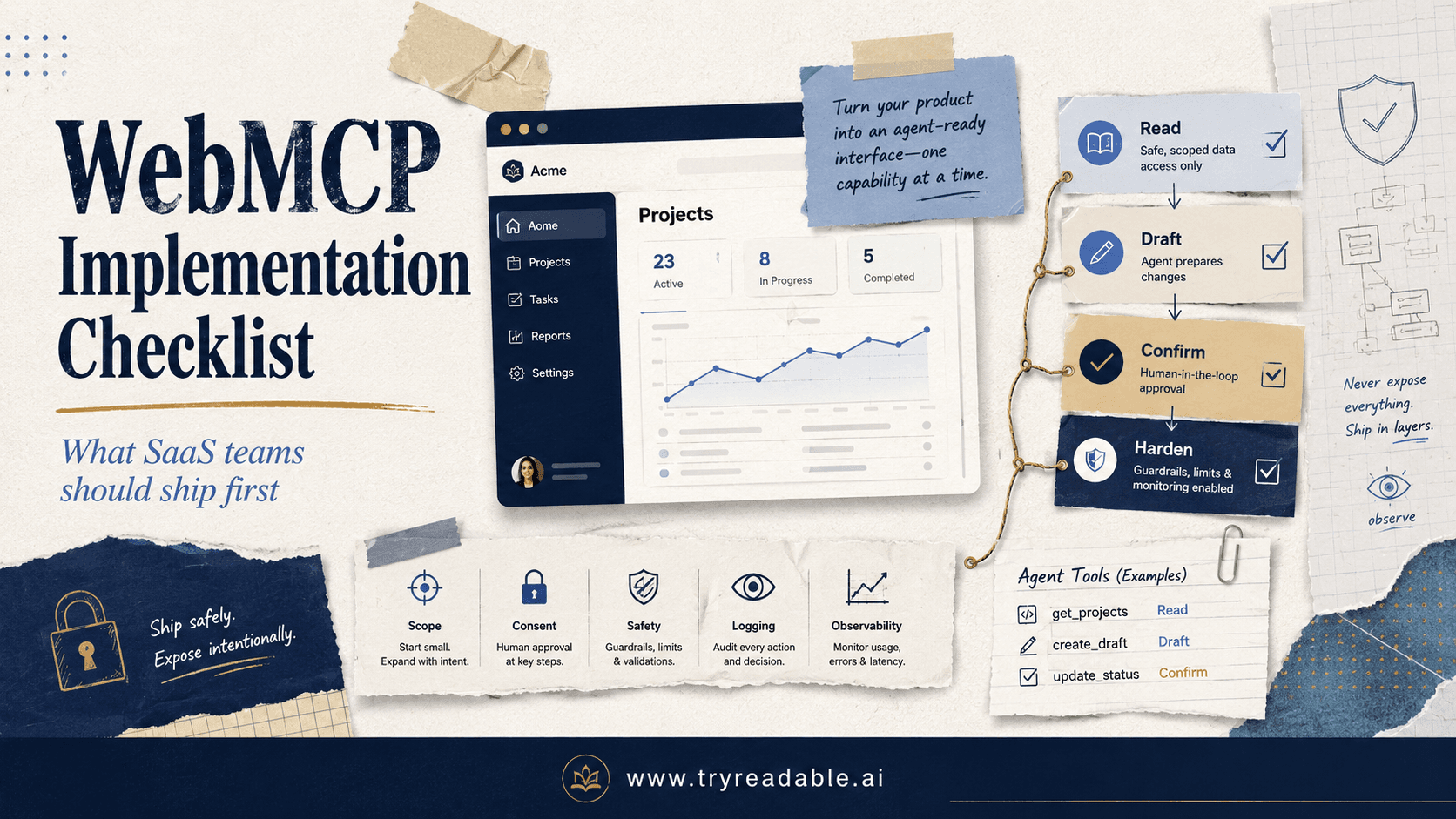
A Practical Security Checklist for Website Teams
Before exposing WebMCP-style actions, ask:
Tool integrity
- Can we prove where each tool definition came from?
- Can third-party code alter the tool after registration?
- Are tool name, description, and schema versioned and reviewable?
Permission design
- Is each action scoped to the smallest possible resource and operation?
- Are mutating actions time-bound and session-bound?
- Does the server enforce the same boundaries the UI suggests?

Consent
- Which actions require explicit user confirmation?
- Does the user see the actual side effect before approval?
- Do we log consent with enough detail to audit later?
Safety operations
- Can we trace every tool registration and invocation?
- Can we disable a broken or suspicious tool quickly?
- Can we detect drift between metadata hints and actual behavior?
Frontend hygiene
- Are agent-exposed actions isolated from unnecessary third-party scripts?
- Are we minimizing runtime mutation of tool metadata?
- Are we keeping sensitive data out of the default action payload?
If your team cannot answer those questions yet, you are probably still in design phase, not launch phase.
When Not to Use WebMCP for an Action
This is an important product decision.
Not every useful action belongs on the website surface.
Sometimes the safer answer is to avoid WebMCP-style exposure entirely and move the action to:
- a backend MCP tool
- a private authenticated workflow
- a human review queue
- a retrieval-only path with no write capability
That is especially true when:
- the action is high impact
- the permission logic is complex
- the user intent is easy to misread
- the page state is unstable
- the action depends on sensitive internal systems
If the action is too risky to express clearly to a user in one confirmation screen, it may be too risky to expose through WebMCP at all.
Where This Fits in the Bigger AI-Readable Website Strategy
WebMCP security is not a standalone project. It sits inside a broader AI-readable website stack.
Your team still needs the basics:
- crawlable content
- reliable structure
- clean business facts
- clear public retrieval paths
That is the layer we cover in What is an AI-native website and why do you need one?, How LLMs Discover Your Model Context Protocol and Why It Matters, and our implementation guide at /blog/webmcp-implementation.
It also helps to remember that discoverability files and action layers are not the same thing. If you want that distinction spelled out, We analyzed 2M AI-agent requests. None asked for LLMs.txt. is a useful companion read.
Security only gets harder when the foundation is weak.
If your website is already hard for agents to read, adding agent-callable actions before you fix clarity, structure, and permissions usually creates more confusion, not more leverage.
The Strategic Takeaway
WebMCP can make agent interactions more useful, but it also makes them more consequential.
The biggest mistakes are predictable:
- trusting metadata too much
- exposing actions with broad permissions
- skipping explicit user confirmation for high-risk steps
- letting third-party runtime behavior touch the tool layer
The emerging research is already pointing in the same direction. Tool descriptions can be poisoned. Runtime tool surfaces can be manipulated. Human-designed pages create ambiguity for agents unless teams design for safety on purpose.
So the right mindset is not:
How quickly can we make the site callable by agents?
It is:
Which actions are safe to expose, under what permissions, with what consent, and with what audit trail?
Teams that answer those questions first will be in much better shape than teams that rush into agent-action demos and retrofit safety later.
Sources
- Anthropic: Introducing the Model Context Protocol
- Model Context Protocol Authorization Specification
- webMCP: Efficient AI-Native Client-Side Interaction for Agent-Ready Web Design
- Build the web for agents, not agents for the web
- When the Manual Lies: A Realistic Benchmark to Evaluate MCP Poisoning Attacks for LLM Agents
- WebMCP Tool Surface Poisoning: Runtime Manipulation Attacks on LLM Agents
Want to understand what this means for your business?
If this topic connects to your growth, content, or product roadmap, talk to us for a deeper read on the practical next steps.