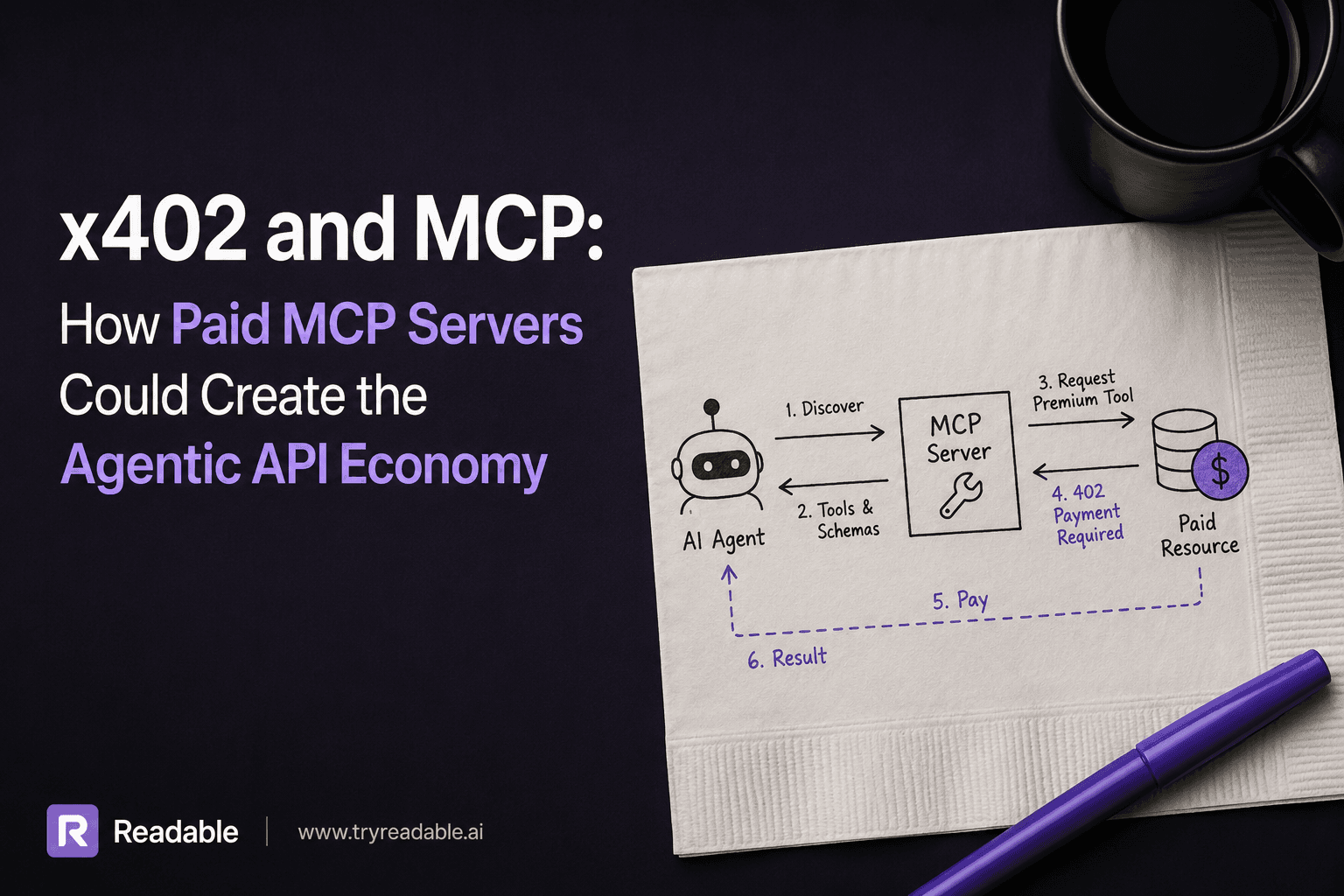
How ChatGPT Finds and Chooses Websites
ChatGPT doesn’t “know” the live internet.
ChatGPT finds and chooses websites by generating search queries, retrieving candidate pages, parsing them under strict time limits, scoring extracted content chunks for relevance, and synthesizing only the highest-confidence sources into an answer.
This is why ChatGPT says ‘pricing not available’ about your product.
Most websites are eliminated long before the model writes anything. If your site fails early in retrieval, your brand doesn’t reach the generation step.
AI visibility is decided upstream by speed, parsability, and extractable clarity, not by design or copy polish.
This process is often described as retrieval-augmented generation (RAG): retrieve first, generate last.
In technical terms, this is a retrieval-augmented generation system, where a search and retrieval layer selects external sources before a large language model generates text from that constrained context window.
The Mental Model Most Teams Get Wrong
Some common assumptions that shape how teams think about AI visibility:
- ChatGPT already knows our site.
- Good content naturally surfaces.
- Brand authority carries over automatically.
- Prompting is the main lever.
These assumptions fail for real-world business queries.
Language models are trained on historical data. They don’t have live access to your current pricing, features, inventory, or positioning. When freshness, accuracy, or comparison matters, the system has to retrieve external sources.
Humans infer meaning from layout, visual hierarchy, and context. Machines operate on text extraction, latency limits, and structural reliability. Which is why a page can look excellent to a human and still be invisible to an AI system.
Below is the practical system that determines whether a website is even eligible to influence an answer.
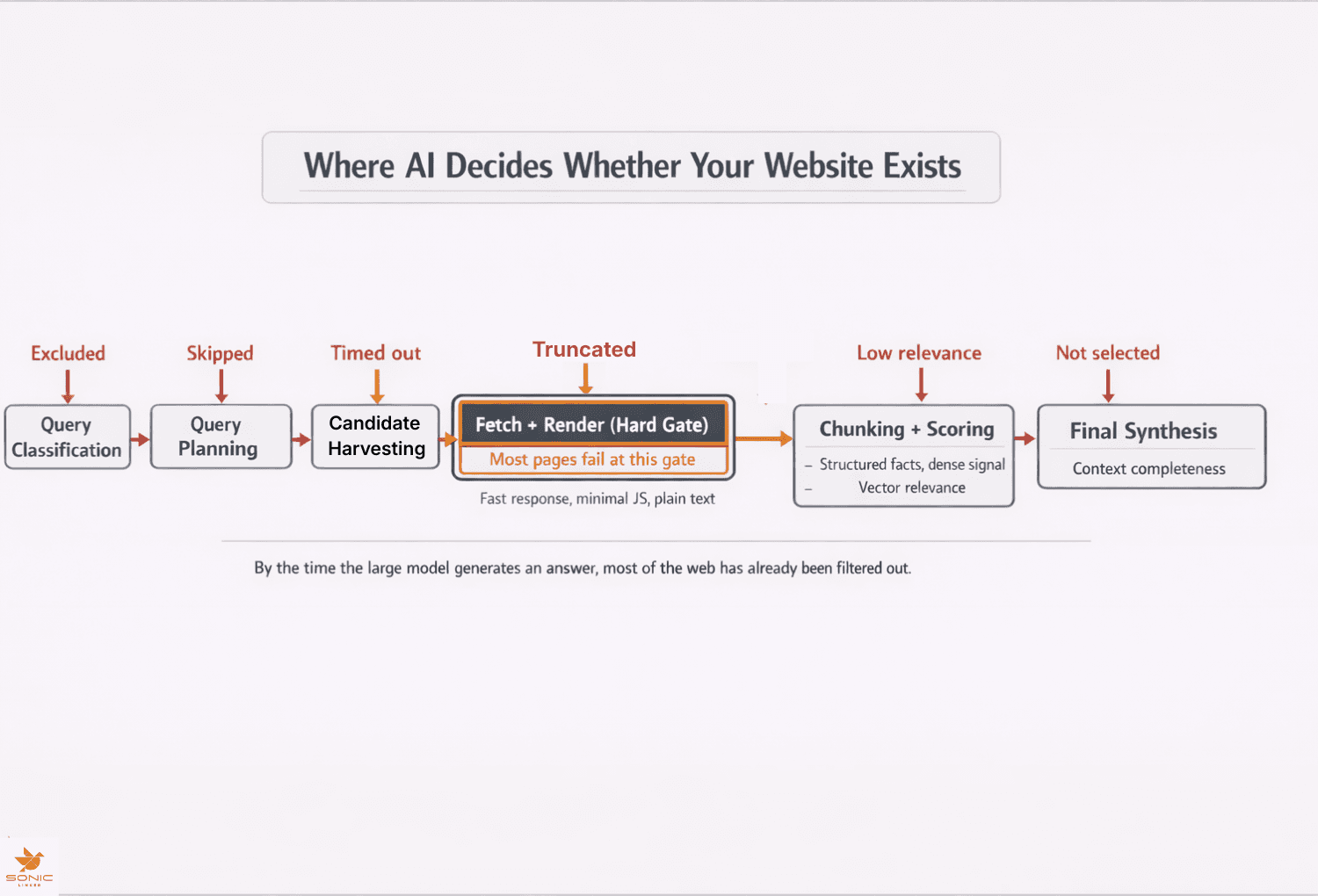
The Retrieval Pipeline Behind a ChatGPT Answer
While implementations keep evolving, the high-level pipeline is generally stable across modern AI systems:
Unlike traditional search engines that build persistent indexes of crawled pages, AI retrieval systems operate closer to real-time fetch and ranking, which means pages must succeed under live latency, rendering, and parsing constraints.
Here is the simplified decision system that determines whether your site ever influences an answer.
| Stage | What Happens | Why Sites Fail |
| 1. Retrieval decision | System decides whether web search is required | Query misunderstood or misclassified |
| 2. Query generation | Multiple search queries are generated | Site language mismatches search intent |
| 3. Candidate harvesting | Pages are collected and lightly filtered | Weak titles, vague positioning |
| 4. Fetch and parsing | Pages fetched under strict time limits | Slow rendering, JS dependency |
| 5. Chunking and scoring | Content split and scored for relevance | Vague language, low signal density |
| 6. Source mixing | External sources may outrank site | Third parties are clearer |
| 7. Answer generation | Model synthesizes final response | Only surviving chunks are used |
Failure at any stage is final. The pages removed early never reach the model. Let’s take a deeper look at each stage
Stage 1 and 2: Deciding What to Search
A small model first decides whether the question can be answered from internal knowledge or requires web retrieval. (Most commercial and operational queries trigger retrieval.)
Next, another model generates search queries. These typically include:
- Short keyword queries
- Longer intent-based queries
- Variations to improve recall
For example, “Which CRM should a 20-person sales team use?” might generate queries related to pricing tiers, feature comparisons, reviews, and deployment size.
This is the first filter. If your language does not align with how problems are searched, your page may never enter the candidate set.
Stage 3: Candidate Harvesting and Early Filtering
The system rapidly collects multiple candidate pages. At this point nothing is deeply read. Lightweight signals dominate:
- Title relevance
- URL clarity
- Domain trust
- Basic topical alignment
Pages that appear vague, overly abstract, or misaligned are removed quickly. Marketing language hurts here because it obscures what the page actually contains. There is no benefit of the doubt afforded here.
Stage 4: Speed and Parsability as Hard Gates
Shortlisted pages are fetched in parallel under tight latency budgets often measured in seconds rather than tens of seconds, which effectively creates a crawl budget similar to traditional search but enforced at retrieval time.
This is where a lot of modern sites fail.
Common failure patterns include:
- Heavy JavaScript delaying visible content
- Important facts loaded only after client rendering
- Pricing hidden behind toggles or modals
- Client-side hydration required to see text
- Large markup slowing parsing
- Inconsistent responses to automated agents
Rendering determines whether content becomes visible in the DOM, while parsing determines whether that content can be reliably extracted and segmented into usable text for downstream scoring.
If the content doesn’t appear quickly and cleanly in raw HTML or early render output, it may never be processed.
This isn’t a quality judgment. It’s simply a constraint problem. A fast, simple page often beats a slow, complex one even if the slow page is written better.
Stage 5 and 6: Chunking, Scoring, and Source Mixing
Pages that survive fetching are split into small chunks. Each content chunk is converted into a vector embedding and ranked using similarity scoring against the original query intent, which favors dense, explicit statements over narrative or implied meaning.
Only the strongest chunks survive.
Practical consequences:
- Narrative structure breaks apart.
- Context can be lost.
- Vague language scores poorly.
- Explicit facts perform best.
Being fetched doesn’t mean being used. At the same time, the system may incorporate other sources such as forums, reviews, documentation, or authoritative summaries.
(These win because they are dense, structured, and unambiguous.)
If your own content is unclear, third-party content may define your brand instead.
Stage 7: Writing the Answer
Only a small curated set of chunks reach the large language model. At this point the model synthesizes rather than explores.
Wording can vary between runs, but the underlying source set usually doesn’t.
You can’t reliably control generation.
But, you can control whether your content reaches it.
If you only optimize copy and UX, you are optimizing the wrong layer.
Generation is probabilistic. Retrieval is constrained and mechanical.
Where Most Websites Break
Most failures are unintentional and come from only optimizing for the human experience.
Typical issues include:
- Meaning encoded in visuals instead of text
- Key facts hidden behind interactions
- Heavy front-end frameworks delaying content
- Information scattered across many pages
- Marketing copy instead of precise statements
- No structured representation of products or policies
Humans can fill in gaps. Machines don’t.
Structured representations such as schema markup, consistent labeling, and predictable page templates increase extraction reliability even when full rendering fails.
A site can convert well for humans and still provide almost no usable signal to AI systems.
From UX Optimization to Retrieval Engineering
Traditional optimization focused on usability, persuasion, and conversion. That definitely still matters.
A second layer now sits underneath it: machine readability and extractability.
Modern optimization involves:
- Fast, deterministic rendering
- Low-latency delivery for automated fetchers
- Plain-text access to critical facts
- High information density
- Stable, predictable knowledge surfaces
This is not about replacing UX. It is about serving two audiences with different constraints.
Trying to satisfy both perfectly with one surface fails.
What You Can Actually Control
You can’t control how ChatGPT phrases its answers.
What you can control:
- How fast your pages respond to automated requests
- Whether critical content appears without heavy scripts
- Whether facts are expressed clearly in text
- Whether content survives chunking and scoring
- Whether machines can extract answers reliably
These are engineering decisions, not branding ones.
Visibility Is Decided Before the Model Thinks
By the time ChatGPT writes an answer, most of the web is already filtered out.
AI visibility isn’t driven by clever copy or visual polish. It’s driven by being fast, explicit, and mechanically reliable inside a constrained retrieval system.
Many brands are already invisible to AI systems and don’t know it yet.
The brands that win in this space won’t be the loudest. They’ll be the easiest for machines to understand.
Would ChatGPT choose your website with confidence?
If speed, structure, and extractable proof affect whether AI systems trust you, talk to us about what your website is making easy or difficult.